Neural Radiance Fields (NeRFs) are a method of scene reconstruction from novel viewpoints. A NeRF network learns a density value as a function of 3D position in the scene. It also learns the color value of a light ray reflected from the scene as a function of 3D spatial position and 2D orientation. By making the output dependent on orientation, the NeRF model is able to accurately represent non-Lambertian surfaces and achieve photorealistic renderings. A downside of NeRF is that rendering a scene can be slow. For pixels in a scene being rendered, a ray is traced out into the scene, and inference must be done for multiple points along this ray. In the original paper, 64 points are sampled initially and then are used to construct a rough probability density function for scene occupancy along the ray. A second sampling is then done, with 128 additional points being sampled from this first pdf. Our goal in this project is to speed up the rendering process by reducing the number of samples taken along each ray without losing too much accuracy.
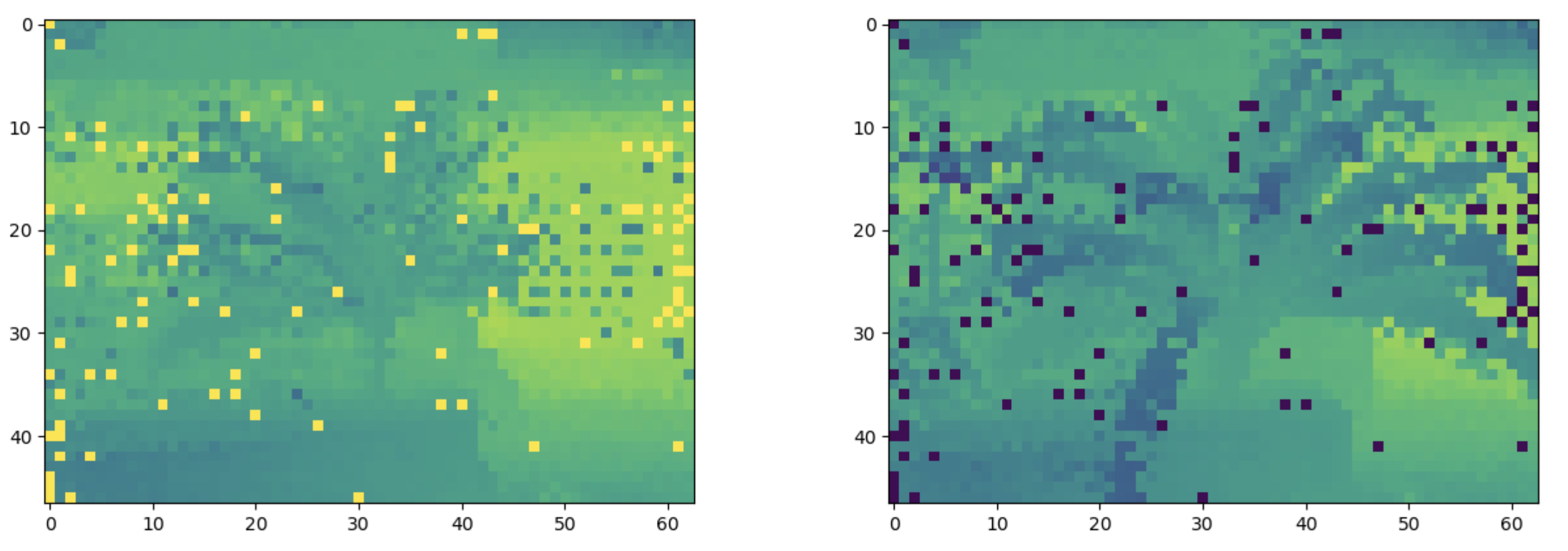
The first technique that we use to speed up the rendering process is to only perform the first round of sampling on some subset of the pixels in our scene.
The second pass is still performed on all of the pixels, and the ray samples for the pixels that didn't get sampled in the first pass are sampled according to the bilinear interpolation of the four nearest pixels that were sampled in the first pass.
For example, if a pixel lies equidistant from the four nearest pixels that were sampled on the first pass, then 32 samples will be drawn from the pdf of each of these neighbors.
Our second approach involves limiting the sampling range along the rays.
To do this, a point cloud of the scene is constructed from the views used to train the network.
Upon rendering a new scene, the points in the point cloud are used to estimate the depth of the scene surface at each pixel.
This allows the ray for that pixel to be sampled around the predicted surface rather than along the entire length of the ray.
With a sparser sampling (1 in 9 pixels sampled in the first pass), the rendering is visually indistinguishable from the original NeRF network.
Quantitatively, we saw a slight drop in the peak signal to noise ration (PSNR), accompanied by a modest increase in speed.

| PSNR | Running Time (Seconds) | |
| NeRF | 23.34 | 16.27 |
|---|---|---|
| NeRF (Sparse Sampling) | 22.84 | 13.99 |
The point cloud method was less successful than the sparse sampling. Due to the vast number of pixels in the training images, our point cloud ended up being very large. Computing the bounds on the rays took linear time with respect to the points in the point cloud, but due to the large size of the point cloud this still slowed the algorithm noticeably. Overall, adding the point cloud to the NeRF framework resulted in a nearly identical PSNR, while moderately increasing the running time. Although this attempt to use a point cloud to speed up the algorithm was unsuccessful, it is possible that in the future we could devise a more clever way to compute bounds using a smaller point cloud.