Reinforcement learning problems are commonly formulated as Markov Decision Processes (MDPs). An MDP is defined by a set of states, actions, transition probabilities, and rewards. When solving an MDP, the goal is to learn a policy that maps states to actions that will maximize the future rewards. There are many algorithms for solving MDPs, but they all tend to suffer from slow convergence when the state and action spaces are too large.
A common method for accelerating learning in MDPs is to introduce abstract actions. Two examples of abstract actions are options, which define a policy over a subset of of the states, and action sequences, which are macros that execute multiple actions sequentially. When useful abstract actions, ones that are likely to appear in the optimal policy, are added to an MDP, they can greatly accelerate the learning process. However, when abstract actions that aren't useful are added, or when too many abstract actions are added, training is slowed down due to the larger action space of the MDP.
Interestingly, humans are able to store a vast number of abstract actions (e.g. kicking, throwing, writing, speaking, etc.) but we don't seem to suffer from the effects of a bloated action space when learning new activities. This can be explained by our ability to identify actions that are relevant to a specific task and selective apply those, rather than considering all known abstract actions. For example, when somebody explains how to play soccer, they might use words like "kick" and "run" that allow a listener to identify relevant abstract actions that they can use while learning the game. The goal of this project is use natural language descriptions of new tasks to accelerate learning by predicting which macro actions are relevant.
First, a set of abstract actions has to be learned. To do this, the SARSA lambda algorithm is used to find optimal policies for a set of MDPs that are different, but share a common state and action space. From the optimal policies, sets of succesful action sequences are extracted. From each action sequence, certain subsequences are selected to be abstract actions based on how frequently they appear and how long they are. Longer subsequences that appear more frequently are preferred.
Next, a Naive Bayes' model is trained to predict which macros are likely to be relevant to a task based on the words present in the task description. Then, this model is used to predict the most relevant macros for a new task description, and the suggested macros are incorporated into the learning on that task.
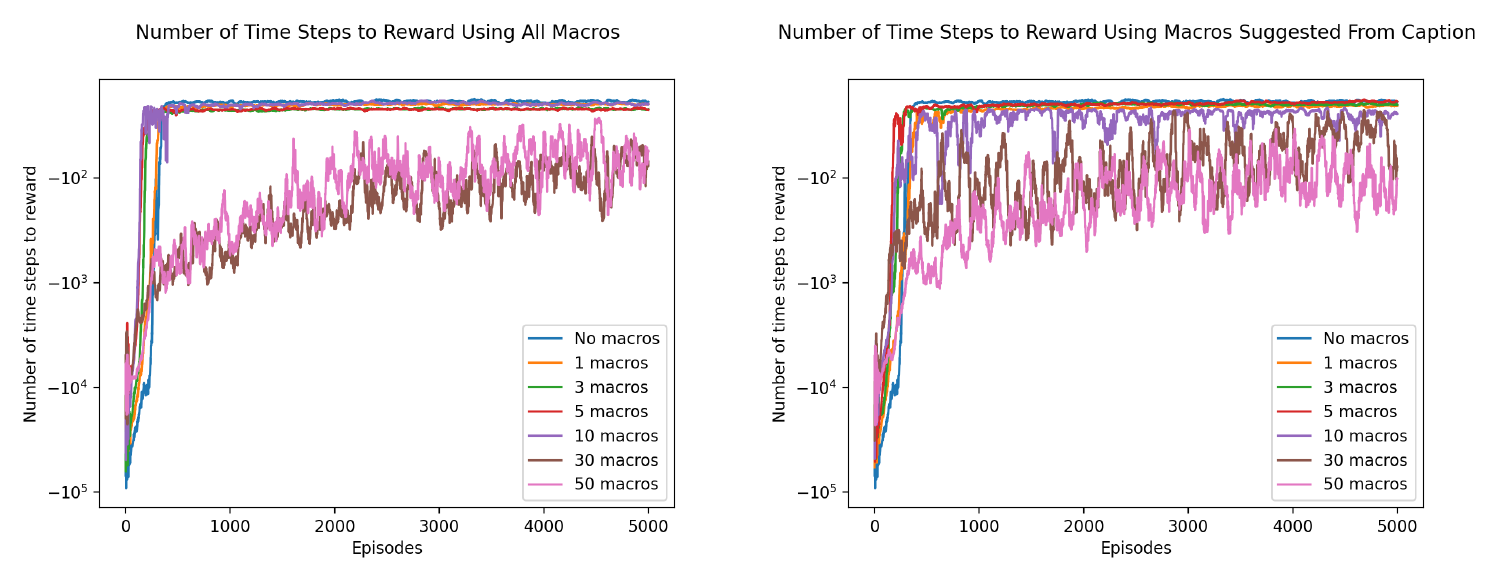
As we expected, the reward curves show that having too many macros can slow learning, while having a few well-suited macros speeds up the learning process.
The results here did not provide strong evidence that using captions to predict relevant abstract lead to faster learning than simply using the most common abstract actions did.
This does not necessarily indicate that our intuition is misguided; it is likely that the problem space used in this project isn't quite complex enough for us to see the benefits of this method.
As humans, we exist and act in an extremely complex world, with infinite possibilities for states and actions. Therefore, it is necessary for us to narrow down the scope of actions that we want to apply to a particular task.
On the other hand, the GridWorld-esque state/action space used in this project doesn't have nearly the complexity as the real world, and it is likely that there are only a few truly useful abstract actions. Therefore, we may not need a task description to predict them.
In the future, I would like to try a similar approach in a more complicated state/action space.